Technical Portfolio 🦾
Here is a selected list of projects I have done, each with a technical challenge I solved along the way. I only feature projects where I was responsible for most or all technical development. For most commercial projects, I was heavily involved in acquisition, UX design and client communication.
Gropius Bau Prisma
I was technical director for Gropius Bau Prisma, an AI-enabled guide to the prestigious exhibition hall Gropius Bau in Berlin. The application is able to recognize context in the exhibitions using the device camera, automatically look up the relevant information from a database, and give visitors in-depth information via a chat interface.
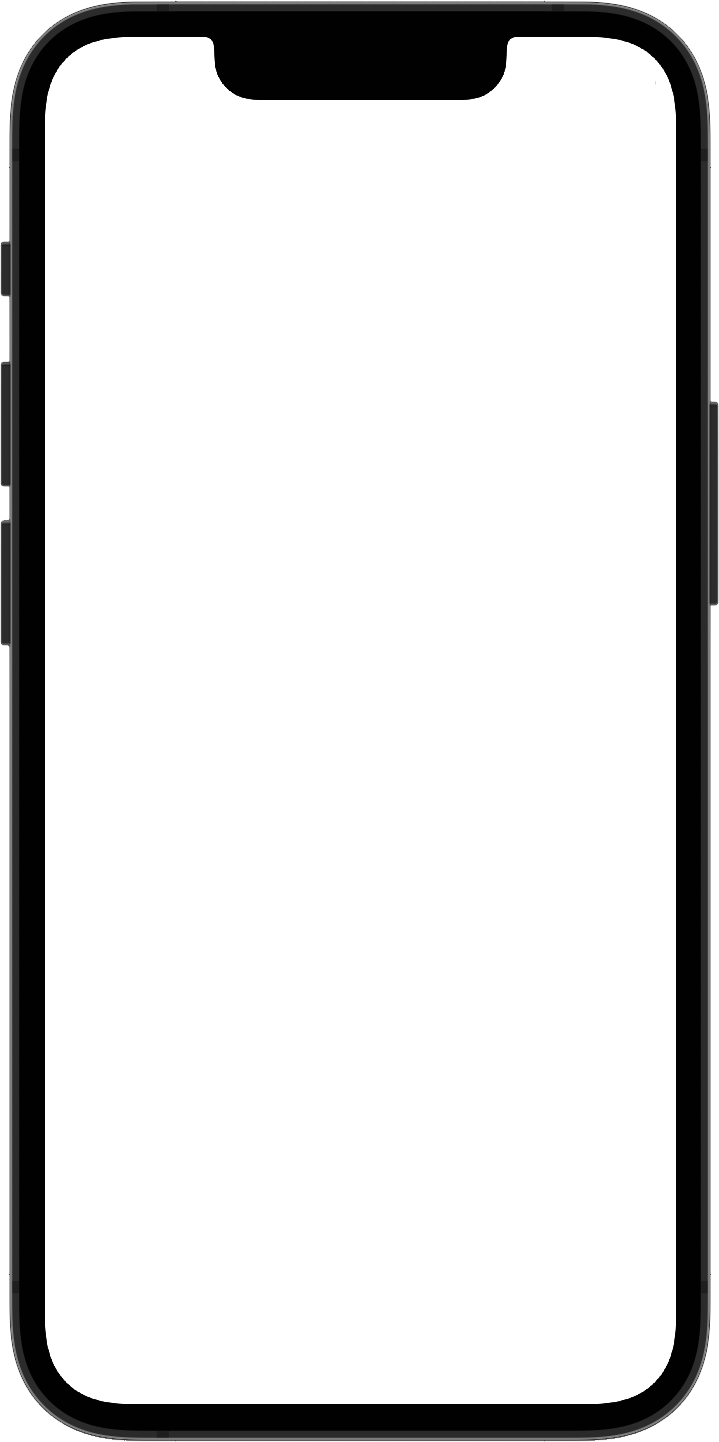

Gropius Bau Prisma has access to a depth of curatorial material, and can therefore give detailed answers to questions about artworks, artists and exhibitions. The app is available in over 50 languages, which we achieved by carefully auditing machine translations.
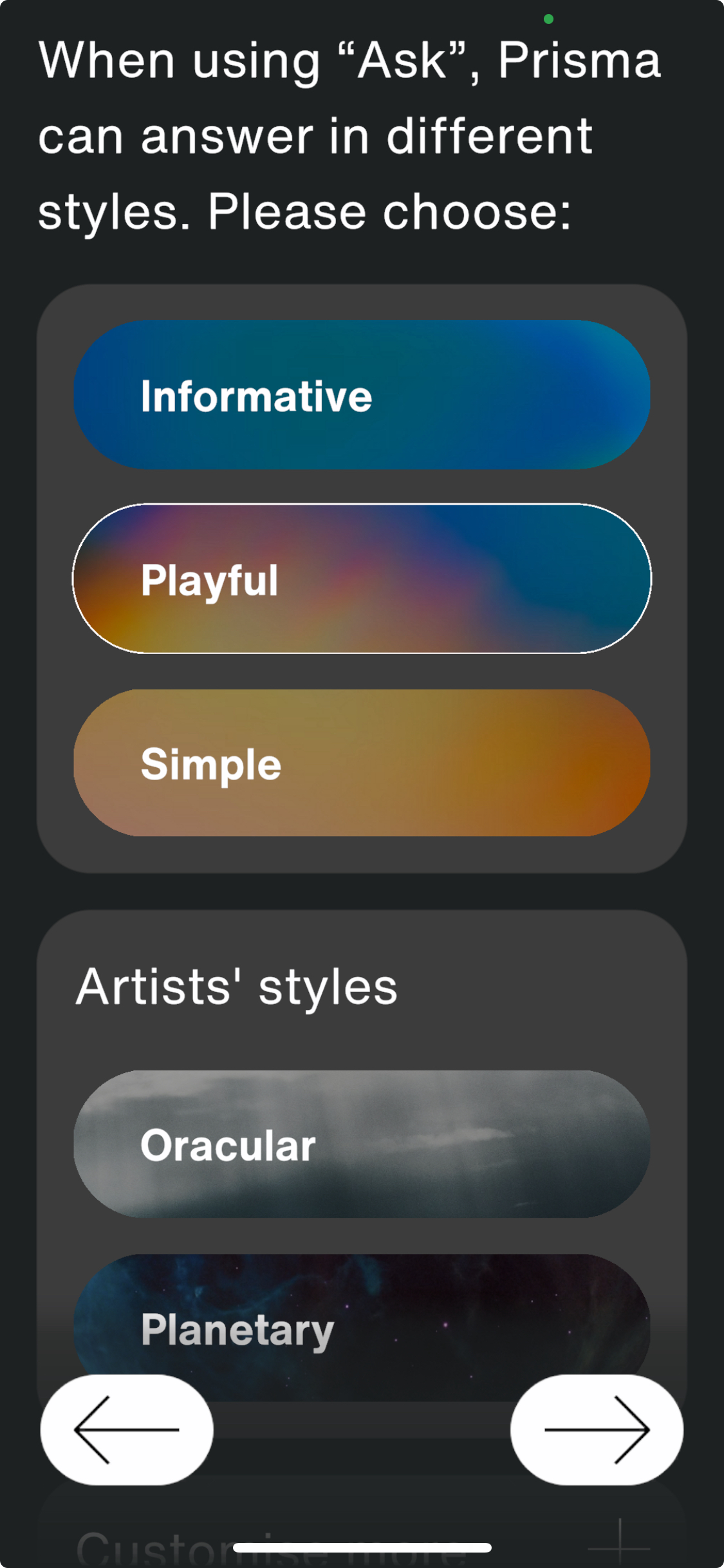
Prisma can answer in a style chosen by the user. A lot of effort went into providing Plain Language, a clearly regulated, more accessible form of simplified language.
One of the most interesting parts of the project is invisible to the museum visitor. The Gropius Bau has new exhibitions every couple months. It was important for the client to minimise the effort required to teach Prisma information about new exhibitions. We therefore built a fully automated data pipeline that populates a structured database of artworks, artists and exhibitions using unstructured information from the curatorial process. Gropius Bau staff can upload pdf files describing the artworks, interviews with the artists, background information about the exhibition or curatorial material about related topics to our system, which are then processed by a Large Language Model to extract structured information and store it in a MongoDB database. This database is then queried by Prisma through a custom-built semantic search, adding context to the Language Model prompt to answer questions in depth. This fully automated data pipeline would not have been possible to build just two years ago, and it enables Prisma to always be up to date with current exhibitions in the Gropius Bau.
Like this, visitors can take pictures in the museum and simply ask What is this about?
In addition to contextful conversations about current exhibitions, this comprehensive software product includes an Audio mode using OpenAI Whisper, a Translate mode using Google Cloud Translate and GPT-4 for Plain Language translations, as well as a tool for live translated subtitles for events at the Gropius Bau.
The Live Subtitles tool transcribes and translates events at the Gropius Bau in real time. It is built on a Node.js + Express backend, Google Cloud Text-To-Speech and Translation, and websockets for distributing translations to visitor's devices.
The frontend of Prisma is built in Unity (main app) and Svelte (Event Subtitles). Unity was chosen to enable Augmented Reality content in the future in the same application, and Svelte was used to enable dual access to Event Subtitles through the web and through the Prisma application.
Try it on the App Store or Google Play!
AI in Warfare Podcast
I am hosting the Podcast AI in Warfare: Perspectives on Autonomous Weapon Systems.
In this series of long-format conversations, I talk to philosophers, legal experts, policy makers, military personnel, technologists and decision makers about Autonomous Weapon Systems.
Whether and how we allow machines to kill people in warfare will be one of the most impactful decisions we make as a society in the coming decades. It is incredibly important to get this right. Many people are calling for an all-out ban on such weapons. This includes my own government in Austria, which hosted the largest international conference on the topic this April. The UN Secretary-General and the ICRC have said in a joint statement that “the autonomous targeting of humans by machines is a moral line that we must not cross”, and the leading AI researcher Stuart Russell is worried that swarms of cheap autonomous weapons might amount to weapons of mass destruction available to non-state actors.
Others think they provide a decisive military advantage. Bob Work, former US Deputy Secretary of Defense, said a ban would put our soldiers and civilians in danger and would be “unethical and immoral”. Ronald Arkin, a roboticist at the Georgia Institute of Technology, even argues that using robots instead of soldiers could prevent atrocities and enable more humane wars.
In this podcast series, I explore these different perspectives and dig deep into the ethical, legal, and strategic implications of autonomous weapons. I examine the technical challenges, potential benefits, and grave risks associated with these systems. My guests bring diverse expertise and viewpoints, allowing me to thoroughly investigate this complex and contentious issue from multiple angles.
The one personal conviction I carry through these talks is that nothing is inevitable. We decide which systems to build and how to use them. If this series makes our collective decision just a little bit more informed, I will consider it a huge success.
ETHx: Autonomous Vehicles MOOC
I have completed the MOOC ETHx: Self-Driving Cars with Duckietown. The course includes autonomous agent architecture, control theory, object detection using CNNs, planning and graph search, as well as reinforcement learning for autonomous agents.
While I was familiar with the modelling and machine learning parts of this course, I learned about control theory, ROS (Robot Operating System), and how to develop with simululations alongside real world agents.
I received a certificate from EdX.
β-Variational Autoencoder
I implemented a β-Variational Autoencoder, reproducing the results in the original paper by Higgins et al. at DeepMind. An Autoencoder is a machine learning model which learns how to represent high-dimensional data in a low dimensional latent space. Conceptually, what an Autoencoder does is fascinating: it automatically destills the important information from your data, and throws away the negligible parts. Once you have this low dimensional latent space, you can also use it to generate new, unseen data. For example, you can generate new images of people that do not exist, and interpolate between data.
Here, you can see input images on the left, which are then encoded into the two-dimensional latent space in the middle. Scroll through the latent space to explore it! On the right, you can see the decoded image. This is really fascinating: only two dimensions are used to regenerate these!
Using a standard Autoencoder, however, this is problematic, since the distribution in the latent space is arbitrary and unknown. Thus, we instead use a Variational Autoencoder, which forces a specific distribution on the latent space, which can then be sampled from. Usually, we use a multivariate normal distribution as the target distribution in the latent space. The name 'variational' comes from the fact that we use a method called 'variational inference' to approximate the distribution of the latent variables. In training, we introduce an additional loss term, the KL-divergence between the current and the target latent distribution. This can be seen as a measure of how far away the current latent distribution is to the target latent distribution. In the DeepMind paper, the authors introduce a new hyperparameter β, which controls the influence of the KL-divergence on the final loss. They give a mathematical justification for this hyperparameter, and show that it helps in creating a disentangled latent space, which is especially important to create an interpretable generative model.
For more details, here is our reproduction paper, and the code for the interactive model above.
AR App Chemnitz.ZeitWeise
With NEEEU, I built an Augmented Reality app to rediscover historical buildings for the Museum of Archeology Chemnitz.
Buildings and places carry a rich history that is easily forgotten when they are remodelled or torn down. AR gives us an opportunity to rediscover the city as it was, and tell a story that seemed lost. Visitors to Chemnitz can discover historical landmarks on a map, compare views of Then and Now in 3D, and see the buildings as they were in Augmented Reality. Along the way, they can find out about the fascinating history of these places.

I built this application in Unity. We used mapbox to show and download offline maps of Chemnitz, GPS position and orientation to place AR content, and Strapi as a CMS so the client can change and curate any information about buildings online.
Try it on the App Store or Google Play!
Humboldt Forum AR App for Guided Museum Tours
With NEEEU, I created an application for guided museum tours for the Humboldt Forum in Berlin. With a networked AR experience, guides can lead visitors through the museum. In Augmented Reality, visitors can interact with fragile artefacts that would otherwise be locked behind glass.
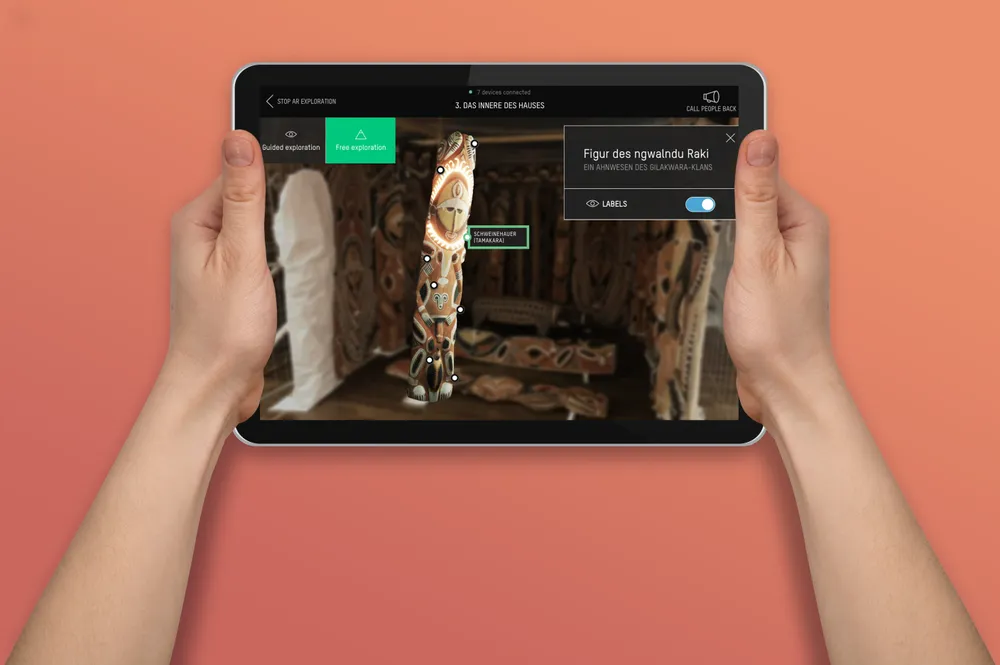
In a tour, every visitor receives an iPad, controlled from the guide's iPad. To synchronise devices, I used a custom-built networking setup built on top of Unity Mirror Networking. A lot of effort was spent on getting networked guiding right: guides can choose which video or AR exhibit visitors see or let them roam free, they can choose which AR objects are highlighted to the visitors, as well as rotate and zoom to show specific parts of the artefact. Enabling guides and visitors to interact with the same AR objects requires synchronised interaction - a bit like collaborating on a document on Google Docs.
To let museum curators edit the content of tours, all content is downloaded from an online CMS. Before starting, all devices automatically download the latest data, cache everything offline, make sure all content is synchronised with the guide's device, and start the guide / visitor connection. This way, guides can show images, scrub videos synchronised without latency, and control AR scenes all without an active internet connection. This was crucial for our client, since the networks at the museum can become unreliable at peak hours.
This application is now used daily by guides in the Humboldt Forum to offer richer guided tours for their exhibitions.
GDPR-compliant data collection App "Anima"
As part of my masters, I created a research data collection application with a focus on transparency and GDPR-compliance. The application collects iPhone and Apple Watch Health data as well as self-reported mental wellbeing data while giving users full information and granular control about which data is being collected. The application is intended to provide a full data pipeline for scientific research: data collection, data storage, legal consent, and an interface for researchers to access the data. In my report, I provide an in-depth overview of the legal requirements for data collection in the GDPR, and derive practical design principles from the legal text.
I chose the type of data collected to facilitate follow-up work that I've been interested in for a while: how well can we predict mental wellbeing from wearable data? People create data about themselves, activities and behaviour patterns in abundance. If we find ways to leverage this data, we can invent whole new methodologies in psychological research and treatment. Traditionally, there is a fundamental divide between quantitative and qualitative research. I believe if we find ways to understand intricate behaviour patterns in quantitative analysis, we can move towards a quantitative reframing of psychology. Hopefully, we will also be able to build products that leverage personal health data for mental health therapy and treatment.
The application was built in Swift, following a Model-View-Viewmodel pattern. Data is collected from Apple HealthKit, which provides access to Apple Watch data. This includes regular heartbeat measures, distance walked, and workout times, but also datapoints like environmental noise exposure. Self-reported mental wellbeing data is collected via a custom interface and data browser in the app. Data is stored and synchronised to a server using MongoDB Realm, which allows for real-time synchronisation across the server and any number of devices. MongoDB employs a NoSQL database on an AWS server in Germany. Once set up, the online server interface looks like this:
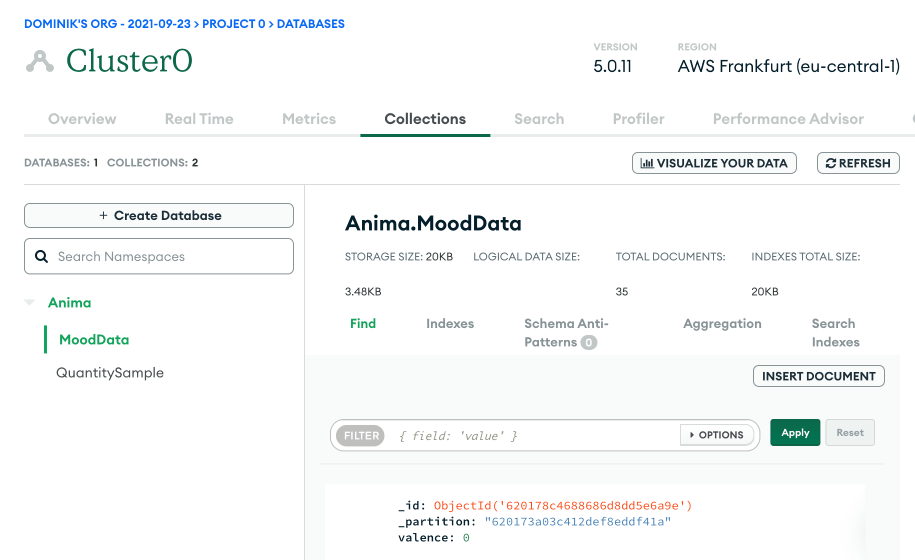
Here, you can see the database for the application, and one datapoint in the list. Each user gets assigned a unique anonymous user ID, and no directly identifying information is stored. Researchers must still be careful when handling and publishing data, as de-anonymization is often possible.
In my project report, I provide a proof-of-concept data analysis using a python API to pull data from the server. In my analysis, I find a correlation between my average walking speed and self-reported mood data, which is a great indication for follow-up work to collect larger amounts of data with many participants and in-depth analysis. For more details, see my project report.
Probabilistic Programming Language
I implemented a probabilistic programming language, a tool for statistical modelling. A probabilistic program is a simulation of a complex random process, such as a biological system, a social network, or a transport network. For example, Uber uses their own probabilistic language Pyro to determine which driver should pick you up when you order a cab. The heart of such a language is the inference engine, which updates the assumptions made in the model based on real world data. A short probabilistic program might look like this:
def coin_flip(samplef, observef, data):
p = uniform(samplef, 0, 1) # our prior belief about how biassed the coin is
# observing real-world data
for d in data:
if d:
observef(np.log(p))
else:
observef(np.log(1-p))
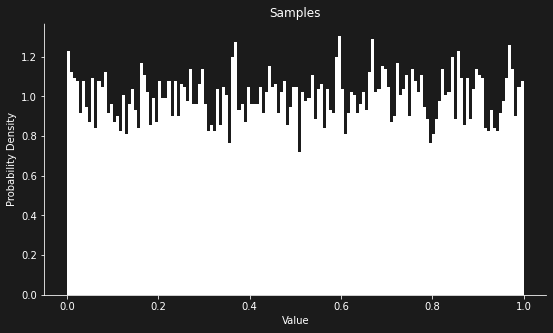
return p# Running inference on the probabilistic program: data = [] # first, running without data, for comparison run_and_plot(coin_flip, data, LMH, n = 10000)
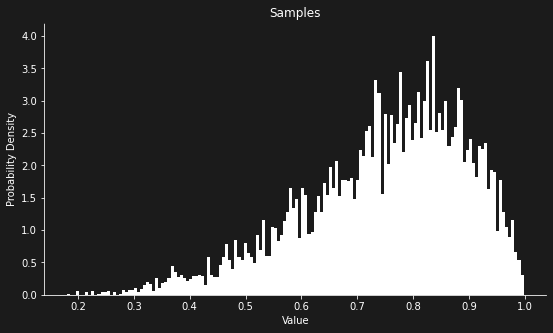
Once we update that prior with data, we get a much better idea over how biassed the coin actually is:
# Running inference on the probabilistic program: data = [True, True, True, False, True, True] # data from a biassed coin run_and_plot(coin_flip, data, LMH, n = 10000)
What's exciting about this technique is that it allows researchers to build models that are too complex for traditional statistical modelling. My implementation features multiple inference algorithms, including Lightweight Metropolis Hastings and other Monte Carlo methods.
This work was part of an exam. The university does not allow me to share the exam paper, but I can share my implementation.
micro:bit Parties Library
During my undergrad, I worked with the BBC Micro:bit foundation to extend the capabilities of their educational programming platform. The micro:bit is a small computer that can be used to teach children how to code. It looks like this:
We worked on a library we called Micro:bit Parties for creating multiplayer games. Because the target audience was kids learning how to code, the library had to be super simple to use. Kids could use Microsoft Makecode or Typescript to build games, like so:
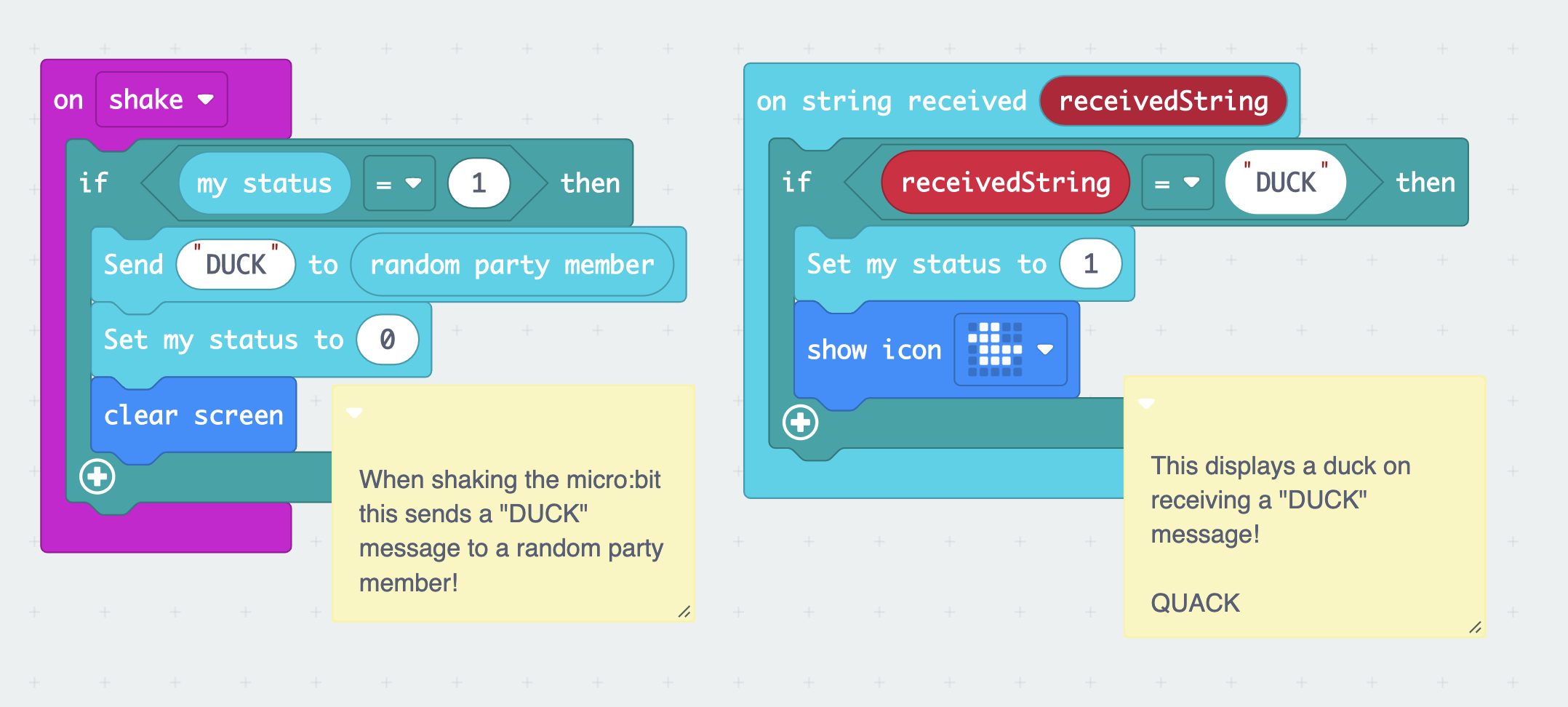
This is a 'hot potato' game where the image of a duck on the micro:bit screen can be passed on to someone else by shaking the device.
Our goal was to make games like these easy to build. To achieve this, we needed a shared list of all micro:bits in a room and enable them to send messages to each other. Our custom light-weight networking protocol sends out a 'heartbeat' on a radio frequency. These heartbeats are used to keep a list of all currently visible micro:bits. Unseen messages are forwarded so they can propagate through the network. This is a serverless synchronisation protocol that requires no setup by the users at all. To get an idea of how messages are sent, here is the function that sends a heartbeat:
void sendHeartbeat(){
if (radioEnable() != MICROBIT_OK) return;
ownMessageId++;
uint8_t buf[PREFIX_LENGTH+MAX_PAYLOAD_LENGTH];
Prefix prefix;
prefix.type = PacketType::HEARTBEAT;
prefix.messageId = ownMessageId;
prefix.origAddress = microbit_serial_number();
prefix.destAddress = 0;
prefix.hopCount = 1;
setPacketPrefix(buf, prefix);
memcpy(buf + PREFIX_LENGTH, &status, sizeof(int));
uBit.radio.datagram.send(buf, PREFIX_LENGTH + sizeof(int));
}For the full implementation, see the parties.cpp file in the project repo.
The Parties Library received an award for the most production-ready student project. The Micro:bit foundation now uses this library to teach kids worldwide how to code.
vvvv - a visual programming language
I worked for the developers of the visual programming language vvvv. A program in vvvv looks like this:
vvvv is used for large-scale interactive media installations. This is how I learnt to code, before going to university. Over the years, I worked on different parts of this comprehensive software product that combines a programming language, integrated development environment, and compiler.
Later, I focussed on teaching vvvv in courses and universities. This was one of the promotional videos for my courses:
Among the courses I taught was a workshop at the RCA in London and a month-long course for master students at the UCL Interactive Architecture Lab.
vvvv is where I learnt to understand programming languages as tools for thinking and creative expression, and what brought me to study Computer Science and Philosophy at Oxford later on.
Visual:Drumset
Alongside highschool, I learnt how to code and built an interactive drumset visualisation. I used it to make a music video together with the DJ project Davidecks & Drums:
I used piezo sensors to pick up vibrations from individual drums, and an Arduino circuit board to process this signal.

I built a custom projection mapping tool in openFrameworks to project on 3D geometry with multiple projectors. Here is a video of first tests I did:
This project won the Ars Electronica Golden Nica, referred to as the 'Oscars of Media Art', in the u19 category.